I'm late responding to this thread since I was on vacation in an internet dead zone (yes there still are such places

)
I think the OP misspoke where I highlighted the quote in red.
In a batch sparge, the gravity of second (and subsequent) runnings will be determined by how much sugar is retained in the MLT/grain after the previous run-off, and how much water is added for the sparge. The higher the grain absorption (and undrainable volume), the more sugar is retained in the MLT/grain, and the higher the gravity of subsequent runnings will be. Since BIAB'ers usually obtain lower grain absorption (and zero undrainable volume), there is less sugar left after run-off, and therefore subsequent sparge steps will have lower gravity than is the case for a traditional MLT. Another way to look at this is that the lower your grain absorption, the less efficiency benefit you will achieve by sparging.
But the above is independent from the dilution math that determines optimal run-off ratios. So BIAB or traditional, maximum
lauter efficiency is obtained with equal run-off volumes. I'll see if I can put together a "reasonably simple" explanation of the math that demonstrates this.
Brew on

Correct will edit, thanks for the catch.
Maximum lauter efficiency is always obtained with equal runnings (for batch sparges), and my past couple brew days have confirmed this. As I mentioned in my pm's though, my
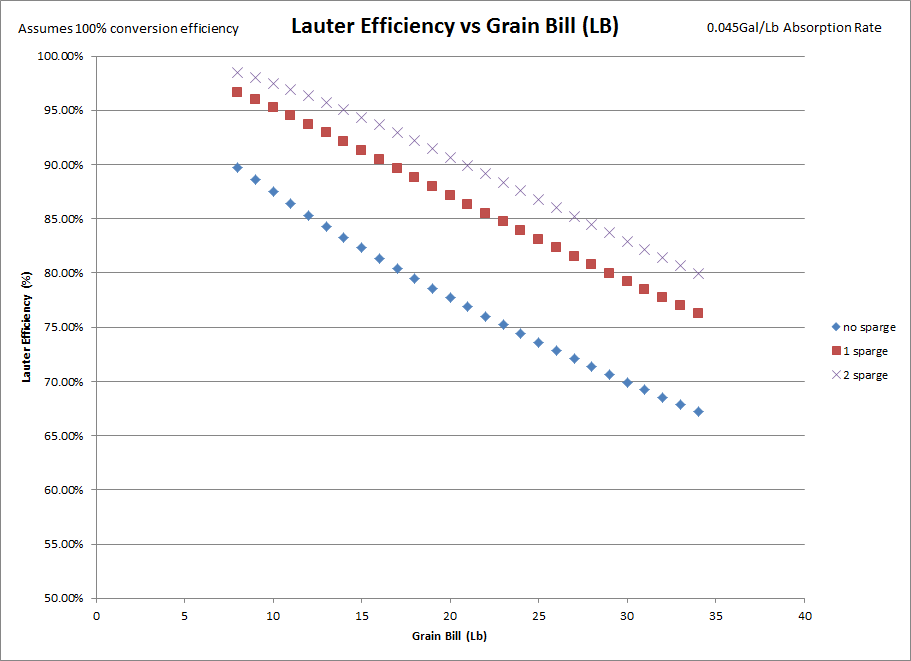
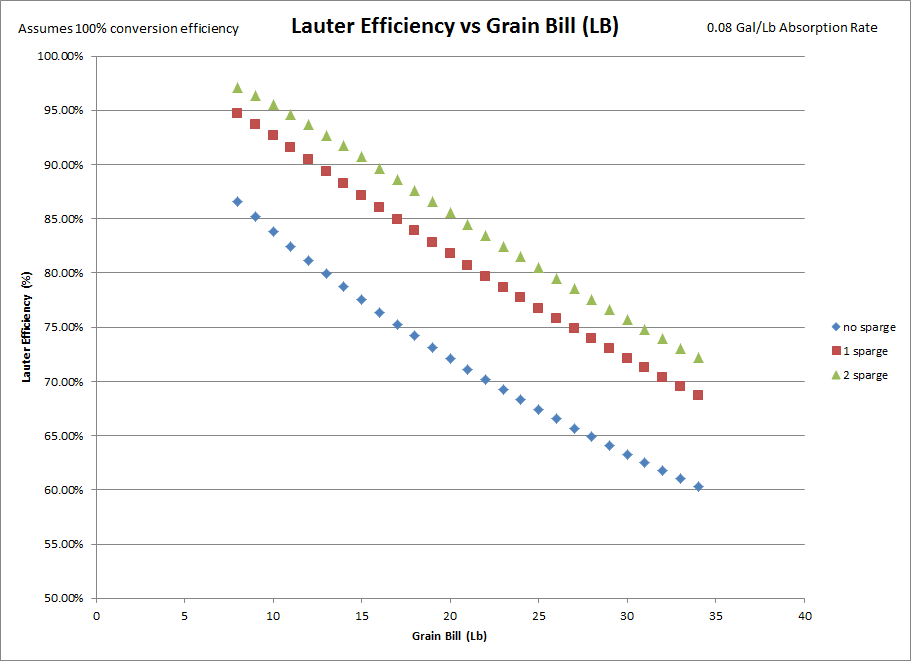
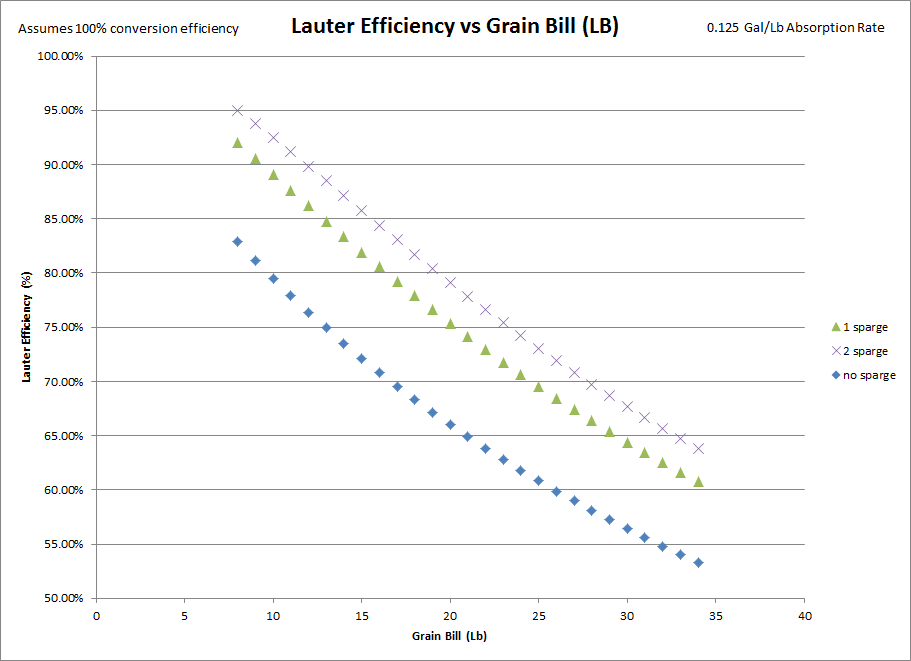
intuition says that conversion efficiency is typically higher with full volume mashes, and so that's why BIABers still get 70-75% as their average while if the conversion efficiency remained constant it may be 65-70%. If you raise your conversion %, by say 5%, then you will compensate for most/all of the loss in lauter efficiency. However I don't know of anyone research done that has found a link between the two, just where conversion efficiency is held as a constant near 100%. For the sake of simplicity, all of the following graphs and data assumes 100% conversion efficiency, so lauter efficiency = mash efficiency. Moreover, I assumed 0 volume loss at the mash tun as this is another variable that has a lot of play but I didn't want to mess with.
Stop, Graph time!

Ran a bunch of simulations using Dougs batch sparge analysis simulator after I made some modifications to it of course, mostly to let me a bunch of simulations at once using what-if data tables.
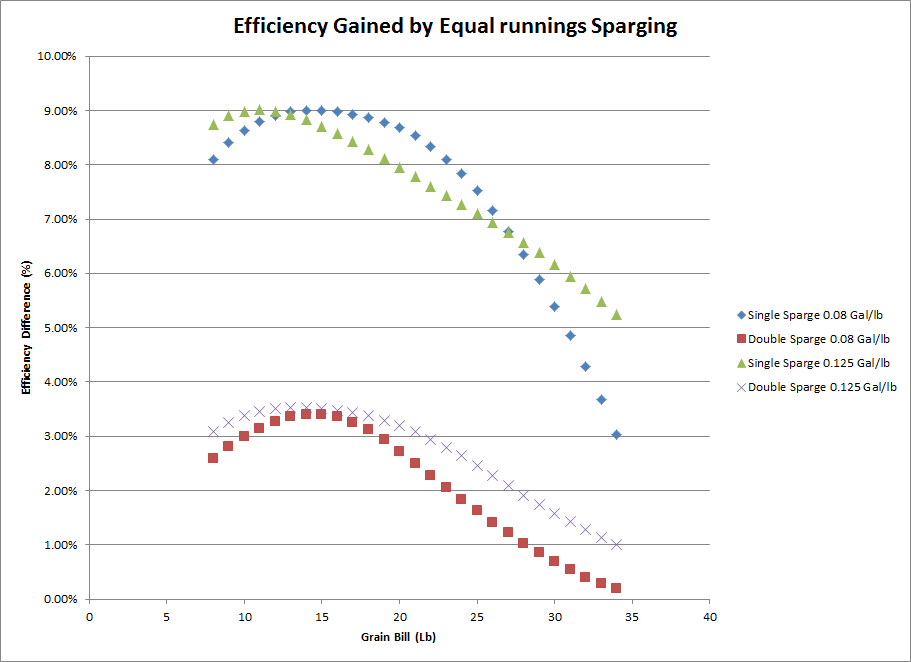
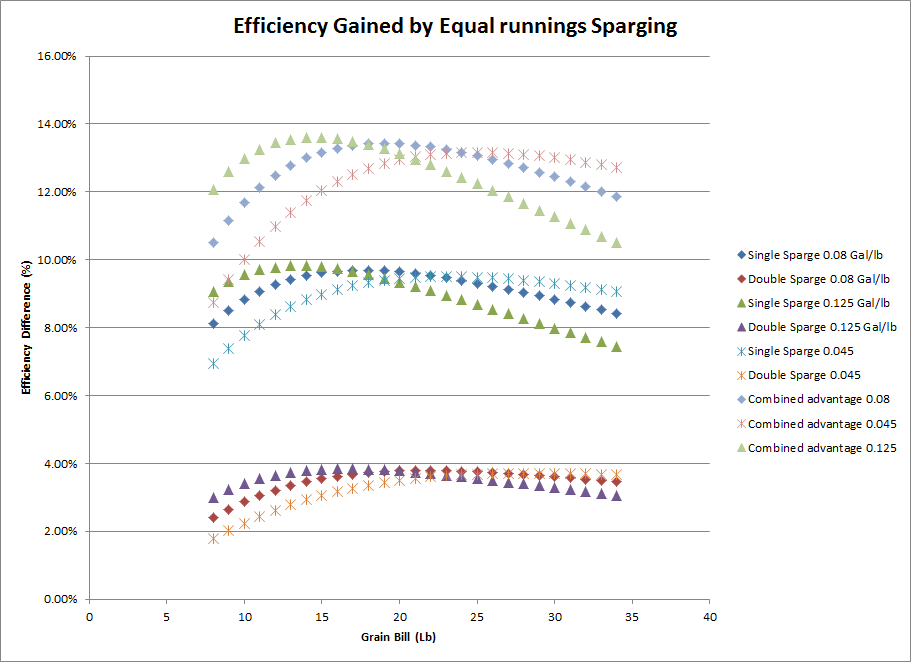
This graph describes the difference in lauter efficiency when performing a no sparge/full volume mash, a single batch sparge with equal runnings, and a double batch sparge with equal runnings.
So for single sparge 0.08 Gal/lb at 20 lbs, the efficiency gained by doing so is roughly 8.9% lauter efficiency. A double sparge nets you an additional ~2.6% lauter efficiency. Together, you gained ~11.5% lauter in comparison to doing a full volume mash.
The interesting thing to me is the very different curves that the data follows, where for traditional mash tun brews a single sparge is nearly linear while the biab sparge falls off much more quickly for very big beers.
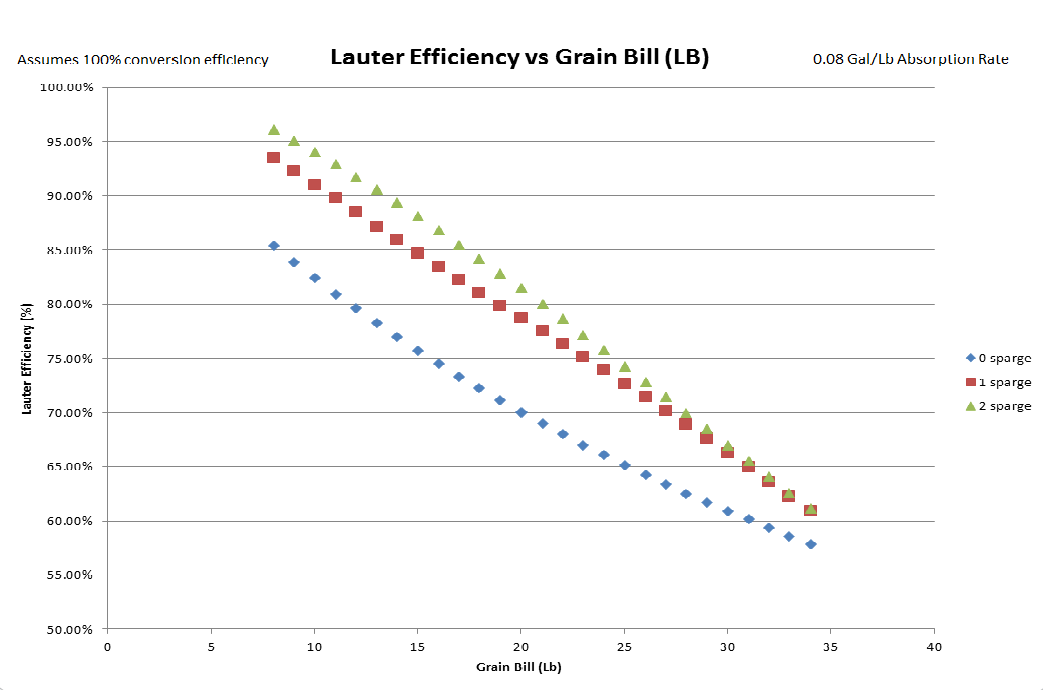
Lauter efficiency as a function of grain bill, assuming the same process and no over sparging and extended boils. Again, you can see the lauter efficiency gains for exceptionally big beers decreases with the grain bill as well as the general efficiency. In my opinion, you would be better off planning for the efficiency loss, and doing a partigyle, than doing an extended boil. Or doing a second very large sparge, and blending the two beers together, but then you have to mess with hop utilization which may be more annoying than it's worth.
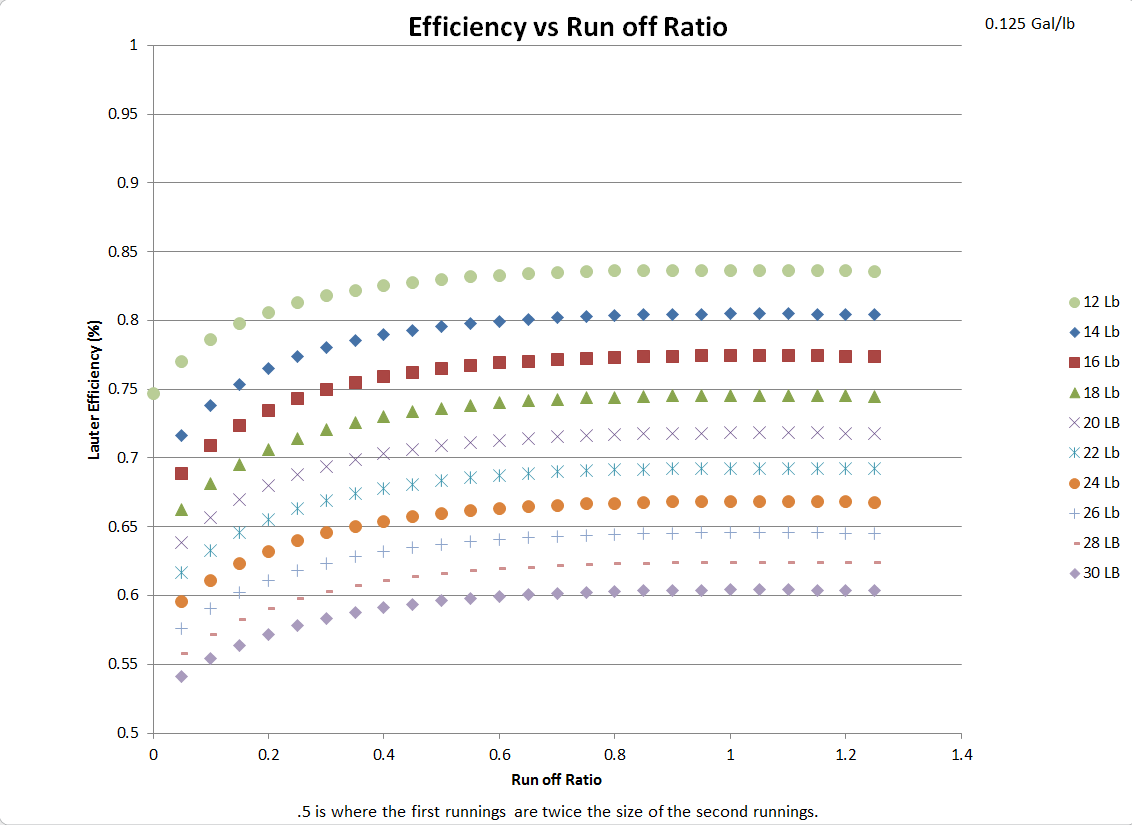
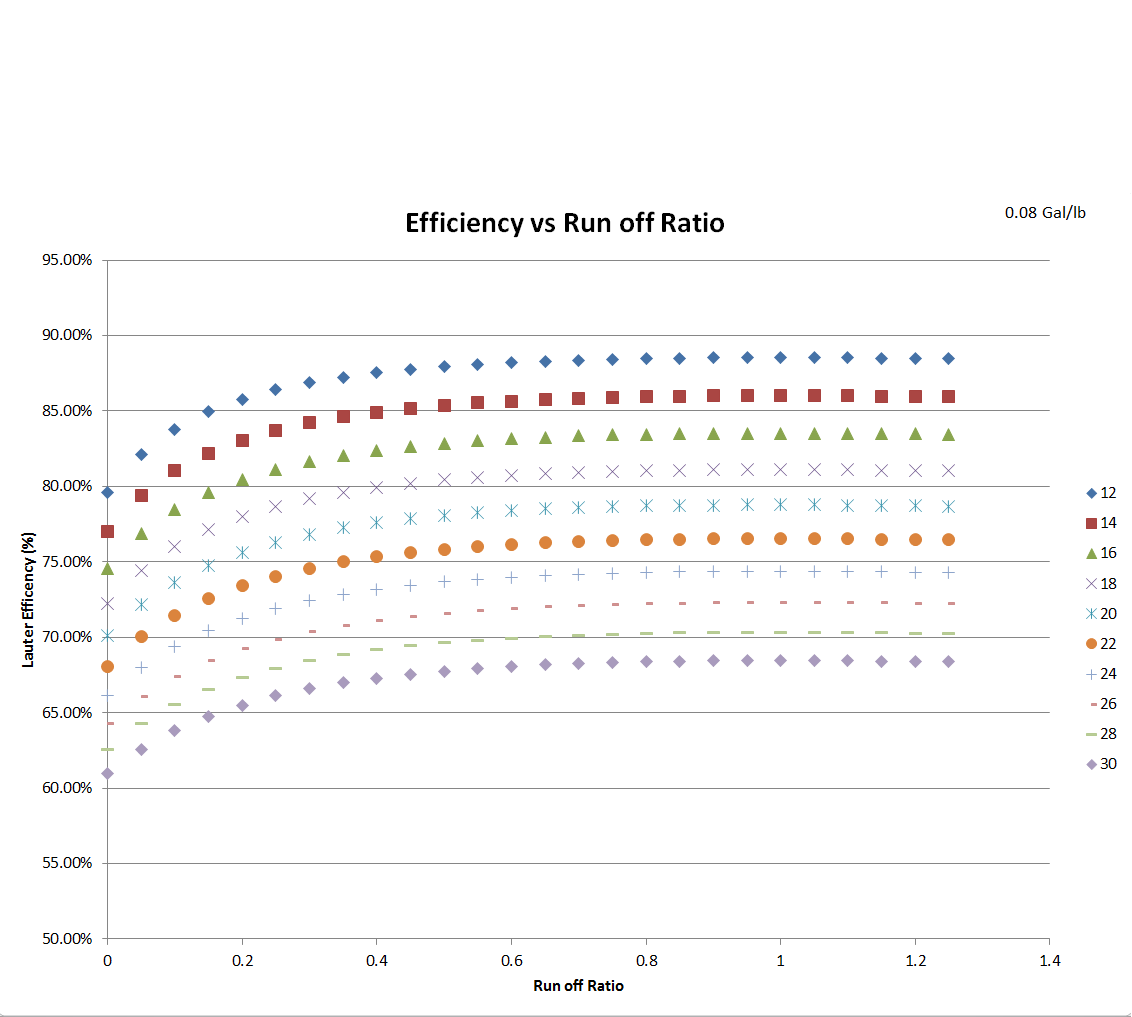
A re-production of braukaisers effeciency curves as a function of the ratio of run offs. Now there's a slight change in terminology definition here, my run off ratio is the ratio of the 2nd runnings to the first runnings, and not the first runnings as a ratio of the total runnings volume. So 1 represents an equal runnings batch sparge, and while his representation was a value of 0.5 which I felt was slightly vague when dealing with more than one sparge...
Anyways, the numbers line up, I only took it out to 1.3 instead of 2.0 because I'm lazy and the graph is symmetric...
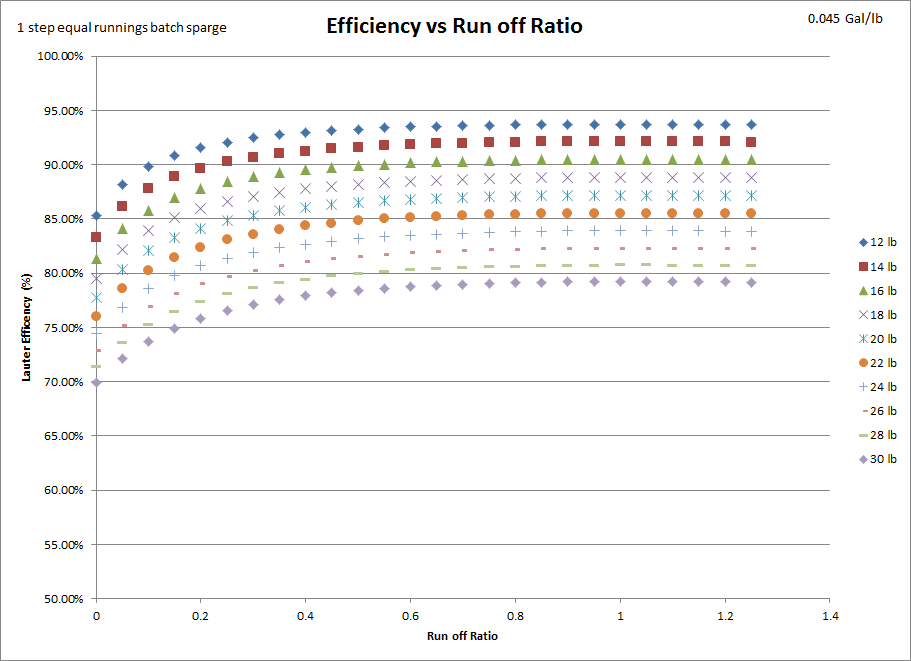
Finally, the graph that started the whole thought experiment. Is BIAB lauter efficiency that much different than mash tun lauter efficiency? Short answer: no. Longer answer: the lower grain absorption, merely translates the curves up and down, it does not actually change the derivative of the curve. So while it does gain you some lauter efficiency, that advantage is relatively constant. As you can see, a similar translation occurs as the grain bill increases.
Hope other people find this interesting and it can provoke some sort of discussion. I'll be implementing a lauter efficiency estimation in my (
http://pricelessbrewing.github.io/BiabCalc/TestingA) with credit to doug and braukaiser.